Louis Motek - LessLoss
-
Panzerholz (Tankwood) is used as the base of the core chassis of F1 cars. Here's a picture of one turned over: We did not choose this material for eye candy. We chose it for its performance. We carried out a calibrated studio comparison of Panzerholz and aluminum and published the results here: https://www.lessloss.com/page.html?id=80 On that page you can find audio examples which you can download yourself and run your own comparison. The difference is enormous. Any current running through any conductor will create some amount of molecular movement. Current is defined as the flow of charged particles. If it did not have any friction it would also not generate any vibration. We are talking not only about miniscule amounts; surely everybody has heard a transformer buzz with their ears directly. Just how that buzz is dealt with through the design of the enclosure will also influence the final results of the audio performance. Here is another set of comparisons, with audio and video examples: https://www.lessloss.com/video_demonstration_of_high_performance_audio.html If the build of an enclosure had no effect whatsoever on the resulting sound, nobody would be found tweaking these things. Returning to the F1 application, you can find more Panzerholz inside the cars surrounding the car's timing electronics. Here is a sliced open F1 car. At around 3:30 you can clearly see the Panzerholz encapsulated onboard electronics: https://www.youtube.com/watch?v=F9WVtZHYjds
-
The Echo's End DAC is made by LessLoss right here in Lithuania. We have here a VAT tax rate of 21% and income tax rate of 15-35%, not to mention mandatory state social security tax. Whoever said that the retail price does not include international shipping is incorrect. Our prices include international shipping via 2-3 day courier with full tracking on every item we sell, including all versions of the Echo's End DAC. Kaiser acoustics currently use the twin enclosure Echo's End Reference Supreme edition, having compared it to other cost-no-object DACs costing $100k. Ours is about one third that price. How do we do it? By being very careful to spend exactly on those features and implementations which bring direct sonic advantage. This is done by a lot of experience and countless direct listening evaluations.
-
To answer this: 11 hours ago, BrokeLinuxPhile said: This statement confuses me, what are they trying to say? I don't get why you need an acoustically dead material here. Speakers makes sense but not a DAC. Thick metal would shield better. Depends on the frequency you want to shield. For instance, in microwave applications, a shield needs to be airtight. Even the slightest slit (for example a hole for a wire to get through) will let microwave radiation though.This is why some shields are soldered shut completely, from all sides. The importance of gaskets in shielding is a well established art. But then there is another thing altogether: each metal type has its own "sound". If you shield with aluminum, steel, stainless steel, iron, tungsten, lead, gold, nickel, etc., you will always have differing sonic results. This sonic coloration comes form the electro-magnetic reflections with said shielding material. Through many experiments, we have come to the conclusion that we don't like the sound of aluminum. It is used a lot in audio these days, and we simply don't like its sound. This is not only an acoustical phenomenon. It is also due to the near-field electro-magnetic interactions. Yes, simply being there next to the circuity, everything colors the sound to some extent. Hence, it is an art to create an enclosure that the designer likes. You have to try many things until you come to such understanding. Some speak of shielding "closing off" the sound. Then there are the famous experiments where you take identical circuitry and build two same-sized enclosures, built only with differing materials, and the sonic results differ quite astonishingly. We like Panzerholz as a build material in this regard, but also for its acoustic properties. When you have any current running through any wire, there will be at a very low level some acoustic vibration (charged particles moving are already a form of tiny acoustic turbulence anyway). When circuitry or any connector is mated directly to Panzerholz, the Panzerholz aborbs a lot of this tiny vibration. This is also why our C-MARC wire is over-braided with cotton fiber. High quality professional microphone cable also always has cotton in it, for the very same reason.
-
I mean that ADCs typically aren't used to convert at 384 kHz. 96, yes, this is ubiquitous, 48 kHz, too, but in recording scenarios it is not a professional standard to record at 384 and therefore anything you see on the music market which claims to be a 384 kHz sampling rate recording is likely a mathematically contrived version of the originally recorded material. This is a heated discussion in the audio recording arena. There might be some scientific applications for recording at 384 like recording bats, but in order for this to be justified, all the gear in the chain needs to have extremely low noise even at ultrasound frequencies in order for the intermodulation effects not to add even more noise to the audible spectrum that we humans can indeed hear. Maybe some rare labs have this capability but for the world of audio this type of extension of sampling rates simply does not add value and can even be (due to interpolation distortions) detrimental to the result. If you ever compare a high jitter recording at high sampling rate vs. a low jitter recording at a low sampling rate, you will always prefer the low jitter recording. In terms of hierarchy of importance with direct relation to sonic quality, low jitter is much, much more important than the difference between, say, 48 kHz and 96 kHz. Today there are even ADCs (AK5397 for example) which can do 786 kHz but it remains disputed as to its usefulness in real-world (human ear) audio applications.
-
Yes, we like to take our every concept to the extreme. That's how we understand the art. Some call it purist. Some call it ridiculous. This reminds me of a whisky label I once saw.

-
The reason we choose the Soekris was because it had the potential through our critical listening tests to outperform our earlier favorite, the legendary Burr-Brown PCM 1704. The Burr-Brown came in selected batches and we always used the best ones. The Soekris also comes in different levels of resistor precision and we only ever use the most precise ones. As for the better sound we are now achieving from the Soekris as opposed to the PCM 1704, I am convinced that much of this has to do not with oversampling algorithms, not with digital filter choices, nor even the exact oscillator chosen. The real reason for the great sound potential comes from the fact that the current and voltage at the actual conversion process, and the trace thicknesses and resistor sizes, are much larger than in a microscopic laser-etched silicon IC scenario. Compounding this, the small signal strength which comes out of the 1704 requires the use of subsequent current/voltage conversion and this means more parts, more powered parts, and thus less purity and more noise. When you listen to the signal coming out of the Echo's End, you are getting direct access to the converted signal. You don't get this from any chip-based converter anywhere.
-
The S/PDIF standard only goes up to 192 kHz sampling rate, and that is the limit we published on our website. The USB input, however, does play 384 kHz sampling rate files, not that any truly exist. This type of talk about sampling rates has absolutely no correlation with sound quality. One can easily devise ways to create lower sampling rate files which sound obviously superior to their higher sampling rate counterpart. All you need to do is tweak the upsampling/downsampling algorithms in order to do this, and the market is chock full of available algorithms. Each has its own sound. The unsuspecting listener often never knows, nor even takes the time to try to inquire, what the originally recorded sampling rate was in the first place. The general mentality and experience in this regard is so narrow and fragile that it is an embarrassment to the entire art of audiophile culture that this topic ever exploded the way it has. Remember the scandalous sampling rate hacks on HDTracks? The publishers would upsample to a higher rate and charge more for the downloads just because somebody passed the file through an upsampling algorithm, something that most any DAC today does in real time anyway, including Soekris. These days, most people listen to conversion being carried out at 384 kHz without their even knowing it. They play what they think are different sampling rate files (not knowing the original recording's sampling rate in the first place, nor having any way of finding out), then listen as their DAC upsamples in real time to 384 kHz, without even knowing it. Those who are quickly excited about sampling rates very quickly get turned off by the math and engineering behind it. It is ironic. Meanwhile, we and like-minded audiophiles are still discovering deeper and deeper depths in good 'ol 44.1. The whole question of sonic discovery in digital always was and always will remain the further and further reduction of jitter. It is just that simple. The whole numbers race in digital audio can be traced back to the analogous numbers race in the competitive field of computer processing. The big difference is that the concept of audio quality is strictly a real-time process, whereas computer processing is always a break-neck speed of churning out of crunched numbers with error correction algorithms with no recourse to perfect timing in real time. Like, why do I have to wait for my cursor on my screen to show me the word I typed half a second ago? I think you get the picture. Latency and multi-tasked resource allocation vs. the smooth flow of real time. The prior easily marketable with faster and faster speeds. The latter boring as hell from a marketing perspective. This is why the higher sampling rate numbers are so much more attractive to those in the selling business.
-
Thank you for the discussion. I will explain this statement from our website: We always know that sonic performance has primarily to do with Jitter reduction, and that Jitter is always going to be contended, since it is impossible to measure with authority. We work by ear where the lab equipment can’t follow. Jitter content in digital streams is reliably measurable only in approximate amounts. Even while it is being measured, it fluctuates in real time. As a general rule, approximately 100 pS amounts are the steps which can be meaningfully measured. It is impossible using any available lab equipment to make authoritative statements about jitter content smaller than this, repeatable from lab to lab by independent researchers. Anything you may have read published in smaller amounts is only marketing hype and nothing else. Let me give you a visual example. In the lab, when you set up a sensitive jitter test, and you do nothing more than wave your hand around the digital cable, the scope shows wild fluctuations of the data readout. But when you listen to a sound system, and you have somebody wave their hand around the digital cable, you don't honestly say you can hear wild fluctuations in the sound quality. This goes to show how this particular measurement is far from the end of the story. Having said that, it is easy to show the correlation of jitter reduction to sonic quality when you use extreme amounts. Comparing 1000 pS to 100 pS jitter content in digital streams is easily measured, shown repeatably on scopes, and easily heard by your average audiophile on any half-decent system. But even this large difference in jitter content can be masked by horrible ambient listening conditions, for example when the floor is made of ceramic tiles or the room has cement walls. Now let us suppose you have a good listening room, a carefully tweaked system, and "authoritative" listening talent. Let's say you've been at this for years. For such a listener, far smaller jitter content differences will have proportionately more and more meaning, until you get to the point where two fanatically determined audiophiles will heatedly argue unto the wee hours about even the smallest changes in jitter content, far smaller than those that are meaningfully and repeatably measurable. When we developed another of our creations, the Laminar Streamer, we tried all manner of oscillators. Here's a picture of a portion of those we critically tested: One of the things we learned from these crucial tests was that Jitter numbers don't say anything about the actual Jitter spectrum, and each Jitter spectrum will produce upon conversion to analogue some sort of sound coloration of its own. This completely apart from the Jitter amount as expressed in pS. So now we have two parameters: Jitter amount and Jitter spectrum. And when listening to all these different clocks under the same conditions in the circuitry, the subjective listening experience again does not seem to correlate with the data. Yes, you can "like" the sound of one spectrum of Jitter more than you "like" the sound of another. This will go all the way deep down the system synergy rabbit hole. These are extremely fine distinctions. Therefore, it is useless and deceitful to publish tiny jitter numbers as some sort of "proof" that your digital solution is better than any other one. It is only useful as a general tool to make sure you are not making any blatant design mistakes. But in the end, it is the ear that decides which solution is ultimately preferred and therefore, hopefully now, the statement that "we work by ear where the lab equipment can’t follow" makes sense. If you ever see Jitter numbers published smaller than 100 pS beware of shameless marketing. At these levels, three labs can give you three different numbers, and a single lab can and most likely will give you three different numbers on Monday, Tuesday and Wednesday.
-
Sorry for the radio silence. The project, for us as a small operation, is very ambitious. You would not believe how many times we have already transported the 55 lbs housings back and forth from Lithuania to Germany, searching for a lacquer formulation which will be pliable enough to withstand the slight but very strong changes in inner tension of the dense Panzerholz material upon travel. We were getting micro-cracks through the lacquer. It's no wonder that nobody uses Panzerholz in this 3D fashion. Even if it is inherently stable, wood is still wood, so it still has some play depending on temperature, moisture, and likely even altitude changes. We've been busy re-vamping the entire schematic because we decided to add some features which necessitated moving some things around on the main circuit board. And because we already had everything calculated to shortest possible signal paths, it became another huge project to redo the entire schematic. There are ways to get this done automatically (by computer programs) with the result that the circuit board becomes four times larger in dimensions, and thus it is lossey already just because of those long signal paths. The Laminar Streamer, in case you don't know, is just a source and contains no analogue output. One will be able to use any DAC one wants with it, and one will be able to use an asynchronously running re-clocking DAC if one chooses to do so. We are continuing to chase our dream and have just received our first batch of circuit boards. Although they are SMT, we are going to put the first couple together by hand and see if there is no mistake. Going to have to get out that microscope...! We did our first silk screen on the plate for the control buttons and for the back panel, but because the back panel is round in shape, the silk screen company didn't have a flat edge to go by and the result came out crooked. So they'll have to do it all over again, and again we wait. All of this waiting is inevitable. We go to companies who have 100+ employees and we say "Hey guys, can you halt your 5 million dollar orders for a while while we give you this really round, strange, heavy, useless item to mill, sandblast, and chrome plate? Thanks, it's ok, we'll wait. Oh, no, you heard us right, it's not aluminum, it's actually steel... Oh, ok, we'll wait longer. No problem..." Then after 10 weeks they send us the results... actually their mistakes... from Austria. So it's been a long waiting game but we continue to work. Here are some pictures. Louis Motek LessLoss Audio
-
My deep dive into media storage interfaces: Musical differences heard between chipsets, Firewire 400/800, USB, SATA, flash drives, SD cards, and network shares (Warning: may cause seizures in the DBT crowd and flat earth naysayers)
Louis Motek - LessLoss replied to Superdad's topic in UpTone Audio (Sponsored)
Alex, This works with MacBook Air (which has no physical hard drive) using any 'standard' audio player like Quicktime or even something more elaborate such as WavePad. A noticeable reduction in Jitter is perceived. What's more, this was confirmed by others running several stages of re-clocking downstream from the computer. It is interesting that this effect comes through even under such "buffered" circumstances. On Windows on a Sony Vaio machine I have a program called WaveLab (Steinberg). And on that software, one can save audio files not only as .WAV or .AIF, but also as .RAW. And when one opens up files as .RAW, a window opens which asks the user to designate what the sampling rate and bit depth are (you have to know this in advance, but I guess it also means you can 'trick' the software as interpreting the files at whatever rate you want). In any case, the best sound is always had by sing .RAW format there. I have also noticed that WAV sounds better than AIF with or without a picture attached to it. That is what initially got me into this file naming business. I reasoned that if the preamble which contains data that there "is no attached picture" affects in some way the audio performance, perhaps the file name does, too. And so it went. The SD Cards that I'd really want to get my hands on are the new ones from Toshiba, currently, as far as I know, only available in Japan: Exceria Pro SDHC™ SD Cards - TOSHIBA Memory 260 MB/s read speed. The fastest I've tried are 95 MB/s. I agree with you. The speed itself is not what is giving the quality of sound. It's just a matter of these faster cards being more efficient. They run off of the same voltage, but if they are offering more accurate data speeds with the same voltage, this means they are more efficient and, hence, are cluttering the circuitry with less noise (= heat). Just like a high efficiency speaker driver runs cooler, so does a more efficient amp and computer or, indeed, any processor. I think that because the digital circuitry is so sensitive to interference with regards to Jitter content, this efficiency parameter is paramount to great sounding computer audio. The "brute force" method of high processor speeds also injects noise into the whole circuitry. This is what someone here on this thread noticed, and therefore lowered processor speeds to discover cleaner and cleaner music playback. Really when you think about it, the completely noiseless digital audio playback system would use every single energy unit of power supply current into the direct formation of the digital data stream, with no heat dissipation whatsoever. So anything done to get closer to this utopian scenario (it seems so far!) aids in achieving ever better sound. I have also noticed that some SD cards have metallic film stickers on them, while others have paper stickers. The paper sticker ones sound just that much better (more natural). The thin aluminum film stickers perhaps ad some small amount of reflections to the EM processes within the card. Probably ideal would be an SD card encasing made out of ferrous iron, to provide close to ideal absorption of stray EM fields. One trick which taught me the perils of thin aluminum in the presence of audio circuitry was to take the entire CD collection and place it all over the gear (not touching, mind you), and comparing that sound with the sound when they are all removed from the system. It was a day-and-night revelation! All those aluminum surfaces caused a lot of reflection in myriad phases and complexity and wavelengths. Louis Motek -
My deep dive into media storage interfaces: Musical differences heard between chipsets, Firewire 400/800, USB, SATA, flash drives, SD cards, and network shares (Warning: may cause seizures in the DBT crowd and flat earth naysayers)
Louis Motek - LessLoss replied to Superdad's topic in UpTone Audio (Sponsored)
(Oh, it seems there's an added space just before the end of the file name. That is not supposed to be there.) -
My deep dive into media storage interfaces: Musical differences heard between chipsets, Firewire 400/800, USB, SATA, flash drives, SD cards, and network shares (Warning: may cause seizures in the DBT crowd and flat earth naysayers)
Louis Motek - LessLoss replied to Superdad's topic in UpTone Audio (Sponsored)
Hi everyone, Fascinating thread. It echoes just about everything me and my audio friends have also been able to confirm. Nice to know that we have moral support. It can get lonely in these "unchartered waters". Try this. Get a file to sound as good as you can on your system. Name it something like: Test1.WAV Make a duplicate of that file. Put it in the same "RAM folder" or SD Card or wherever the best playback place for you is. Name the duplicate the following (cut and paste it): XX���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������.WAV If it refuses to play, shorten the filename until it plays. (It seems different playback software has different requirements). Listen to the difference. Do you like it? I don't have a scientific explanation, but can say that it took a lot of man-hours to pinpoint this "Jitter-bug" of computer audio. The 'strange symbol' here is the one which corresponds to the binary code for "all ones." The two "X" symbols can be anything, like 00 or 01 or whatever, just in case you want to make more of these long file named gems. You probably will... Enjoy! Louis Motek -
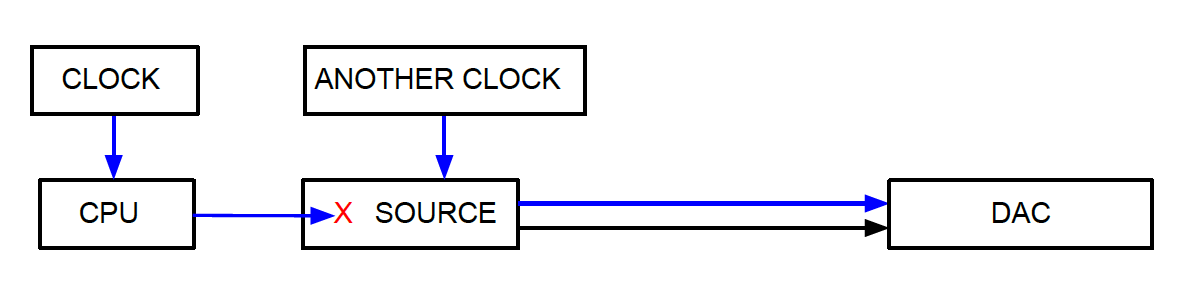
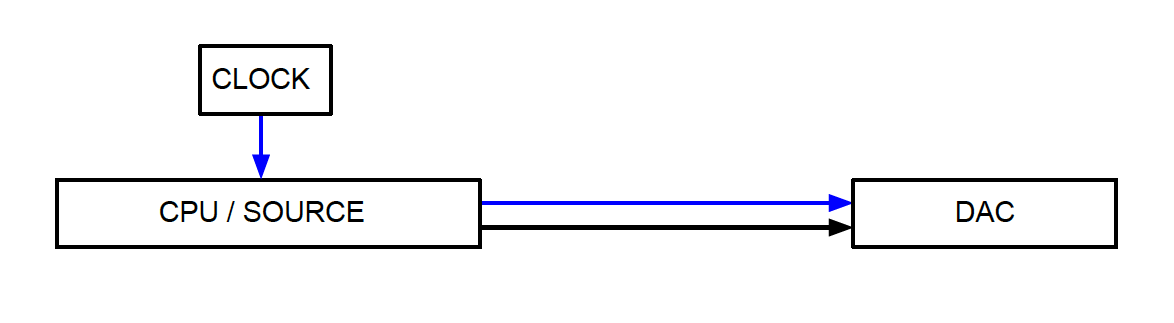
This last question is one which has come up before (even to ourselves!) and will inevitably come up again, so I think a differentiated response is in order. Yes, one would think that in all cases, a proper Master/Slave relationship with the DAC Master Clock synchronously re-clocking the digital stream coming from a synchronously slaved digital source device would always create the best conditions for the lowest possible Jitter at the moment and place of D/A conversion. And, for many years, this is exactly what we at LessLoss offered. Today we see this in a little bit different way, which requires a little bit more differentiated thought. Let's start with a synchronously slaved DAC scenario, then we'll go to asynchronous re-clocking (two clocks), then we'll get to synchronous re-clocking (one clock), and then we'll go back to the synchronously slaved DAC scenario. Synchronously slaved DAC scenario [ATTACH=CONFIG]5346[/ATTACH] In this scenario, any clock Jitter which is present at the place and time of source clocking will contribute to distortion of the analogue signal after D to A conversion. In other words, you get what you get; it's that simple. If you have a bad clock, you will have bad sound. If you upgrade the clock, you will have that much better sound. If you have a better shield on your digital cable, you will have better sound as well. Everything that happens at the source has direct relation to sound quality after D to A conversion. For better or for worse. There's another way to do it, though, called: Asynchronous re-clocking [ATTACH=CONFIG]5347[/ATTACH] In this two-clock scenario, the separate, second clock which runs the DAC process disregards the original clock which came with the data stream. This cutting off of the original clock timing and re-clocking it with a second, independent clock source is called asynchronous because it is not a process which is locked in time. No two clocks can ever run at the same speed exactly. Slippage between them occurs. This slippage, however, causes very little Jitter. Much less, in fact, than the "cheap" clock and perhaps cheap digital cable caused which was originally used at the source. Hence, the solution results in a huge upgrade in sound quality over the synchronously slaved DAC scenario above. There is, however, a threshold of performance which the 'source clock' must be worse than in order for the asynchronous re-clocking scheme above to perform its magic. If the 'source clock' and digtial cable technologies were in fact better than the 'other clock' above, and if the 'other clock' is performing worse than the 'source clock' by the time the 'source clock signal' arrives at the DAC, then we have a downgrade in quality and the asynchronous re-clocking DAC is now performing more harm than if that second clock were turned off. Now we come to the crux of the matter. We come to the part that (it seems) only very few people are cognizant of. And this pertains to the "holy grail" of: Synchronous re-clocking [ATTACH=CONFIG]5348[/ATTACH] Now we have only one clock, so we have no more 'slippage' between two clocks running at different rates. So far so good. We also disregard the clock signal which went all the way around from clock to source and back again, this time paired with data from the source, all the way back to the DAC chip. We disregard it because it is known to now contain more Jitter than the clock source it originated from, which is right here and available anyway. So we disregard the 'long travelled' clock and we pair the data stream with the original clock it was born from. Voila! Perfect synchronization and perfect Jitter reduction! Right? Almost. As it turns out, this synchronous re-clocking can be outdone by the more simple system of a synchronously slaved DAC scenario above, provided HF reflections are attenuated amply and provided the original clock signal used in both cases be of ample high quality. What's striking is the following. There is a threshold of Jitter content which much be present in order for the asynchronous re-clocking scenario above to improve upon it. If this threshold of Jitter content is not met, the solution actually degrades the sound quality by introducing more jitter than there was to begin with. In the same way, in the synchronous re-clocking scenario, where there's only one clock, if the clock signal travels full circle and does not get corrupted, and is then discarded and re-clocked, we are actually loosing quality we would otherwise have gained had we simply disengaged the re-clocking function altogether. But in this case, which, granted, is indeed a special case, we should have simply placed the high performance clock in the source device to begin with, to save us that extra first leg of distance altogether! It is ironic but in a way beautiful that when we follow all of these steps full circle, always improving upon each and every step, we are led back to the very beginning where we started from, this time at a higher level of performance due to the use of a very high quality clock source and because we have properly dealt with high frequency reflection attenuation and minute acoustical vibration issues. Once we are back at square one, we realize just how true the saying is that "simpler is always better". In other words, the moral of the story is "It is laudable to fix mistakes that happened, but if it ain't broke, don't fix it!" Enter computer audio clocking This is the way computer clocking works before the audio is streamed out to a DAC. Again, we have the issue that the CPU runs at a different speed as the source which streams the data. Buffering and synchronization issues must be overcome through that inevitable 'slippage' between multiple clocks and this always causes Jitter. And so our solution is: It required of us to engineer our own operating system from ground up, because no pre-written modules existed which did what we needed the OS to do in a direct drive setting without 'clock slippage'.